
Distributed Reporting Mesh with Duckdb and Streamlit
Is all data big? Not really. I wanted to find a solution to setting up a lightweight reporting mesh to compliment distributed storage in a data mesh. Is there a way we can create distributed small instances of reporting applications that provide compute on demand whilst also source controlling the visualisations? I then discovered duckdb and streamlit realising that I could indeed create a lightweight and source controlled reporting mesh with tools already available. I quickly jumped on to kaggle to find a nice dataset to prove the experiment - say cheese…!
- Pre-Requisites
- Environment Configuration
- Cheese Data from Kaggle
- DuckDB
- Combining Streamlit and DuckDB for the App
- Containerising the App
- Deploying to Azure Container App
- Summary
Pre-Requisites
As always I will be using the mighty gitpod so I won’t need to configure any of the above other than spinning up a workspace.
Environment Configuration
Requirements File
The following libraries will be required so we will create a requirements.txt file to install them.
duckdb==1.1.1;
streamlit
plotly
Pip Install
we’ll then install these with pip.
pip install -r requirements.txt
Gitpod Configuration
If you’re using gitpod you can use the base image at it contains a python version by default. If you configure the gitpod.yml as per the below then it will install the dependent libraries for you on starting the workspace as well as install some handy VS Code extensions.
tasks:
- name: Pip Install
command: |
pip install -r requirements.txt
vscode:
extensions:
- ms-python.python
- randomfractalsinc.duckdb-sql-tools
- evidence.sqltools-duckdb-driver
- cweijan.duckdb-packs
- whitphx.vscode-stlite
- azuretools.vscode-docker
Cheese Data from Kaggle
I recently discovered the website kaggle that has loads of open source datasets for data science and experimentation. After a quick search for cheese and wine I found the following datasets to satisfy my cravings:
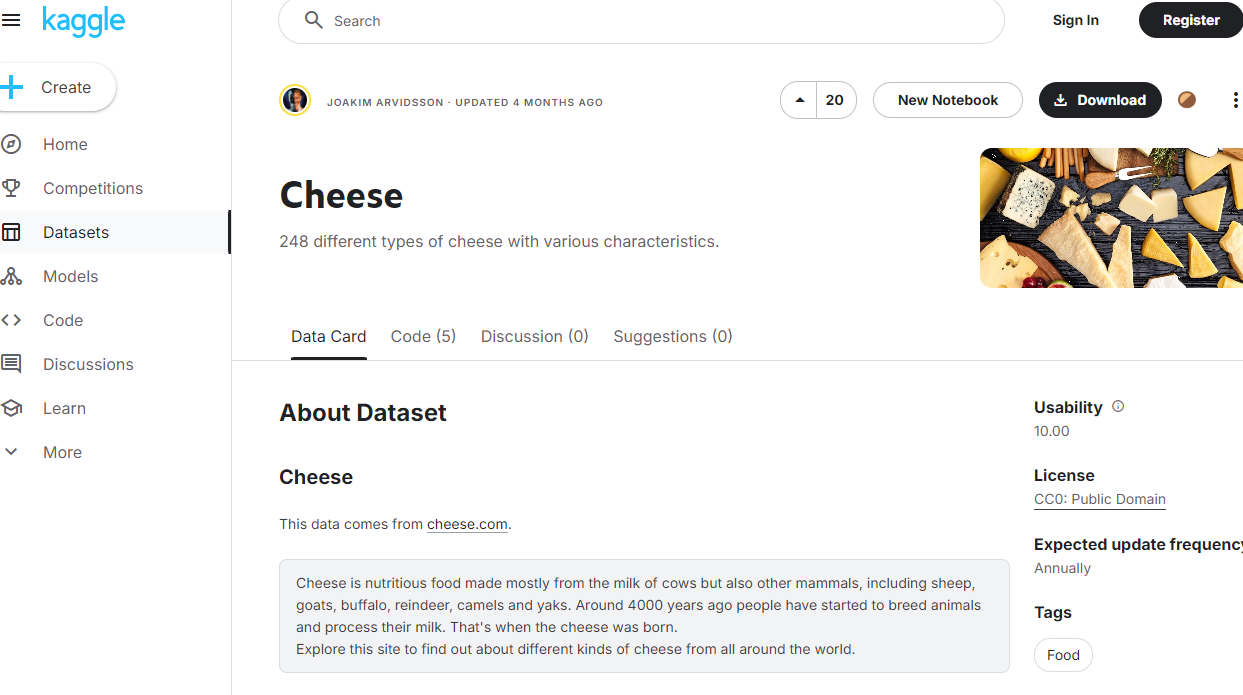
A quick review of the license attributed to both made me realise these were good to go and experiment with!
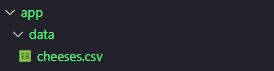
I therefore downloaded the cheese dataset and uploaded it to a local “data” directory in my workspace.
DuckDB
Duckdb is a lightweight, in-process SQL database management system. It is the OLAP equivalent of the transactional SQLLite and designed to be as easy to use as possible. It requires very little effort to install and you can use via the command line or via a python interface - the duck db library we have already installed above! I love how simple it is to use and the fact I do not need to perform any heavy configuration to get it to work. There is host of documentation out there and mother duck is a great resource along with a free ebook. Duckdb made me realise how much we have been sold “Big Data” and that not all our data needs are actually that big! If you want to query up to a few hundred gigabytes of data then duckdb is a great choice due to its simplicity and speed.
Using the python interface we can query the cheese data as follows:
import duckdb
con = duckdb.connect(database="./data/cheese.duckdb", read_only=False)
duckdb.sql("CREATE TABLE cheeses AS SELECT * FROM read_csv_auto('./data/cheeses.csv');")
duckdb.sql("SELECT * FROM cheeses LIMIT 5;").show()
duckdb.sql("DESCRIBE SELECT * FROM cheeses;").show()
duckdb.sql("SHOW TABLES;").show()
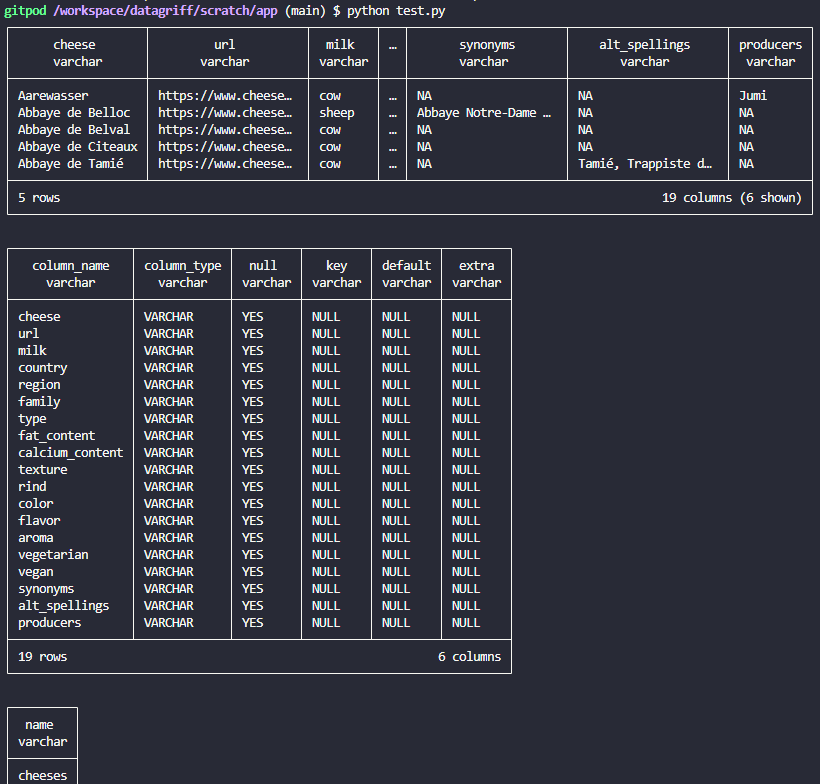
This has queried the top 5 of the cheeses data, described the schema and also queried the database to show all tables available. I had some issues querying in SQL in a cloud developer environment in VS code so this will be something I will have to look at further. However the fact I can query data in a few lines of code without any heavy machinery is exactly what I need, so now I just need to make it look pretty in a reporting application. Enter streamlit…
Combining Streamlit and DuckDB for the App
Next I wanted to create a multi-page app. Using what I had already learned from my duckdb experimentation I setup my first page of my streamlit app in a main.py file with the code below. This setup a cheesy page title for the streamlit application and connected to the duckdb database to query the cheeses data.
import duckdb
import streamlit as st
st.set_page_config(
page_title="Cheese",
)
st.write("# Cheese")
con = duckdb.connect(database="./data/cheese.duckdb", read_only=False)
duckdb.sql(
"CREATE TABLE IF NOT EXISTS cheeses AS SELECT * FROM read_csv_auto('./data/cheeses.csv');"
)
To run the streamlit app you can use the following command:
streamlit run main.py
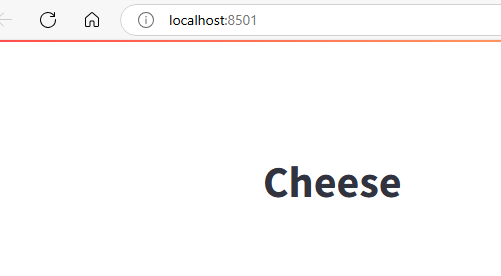
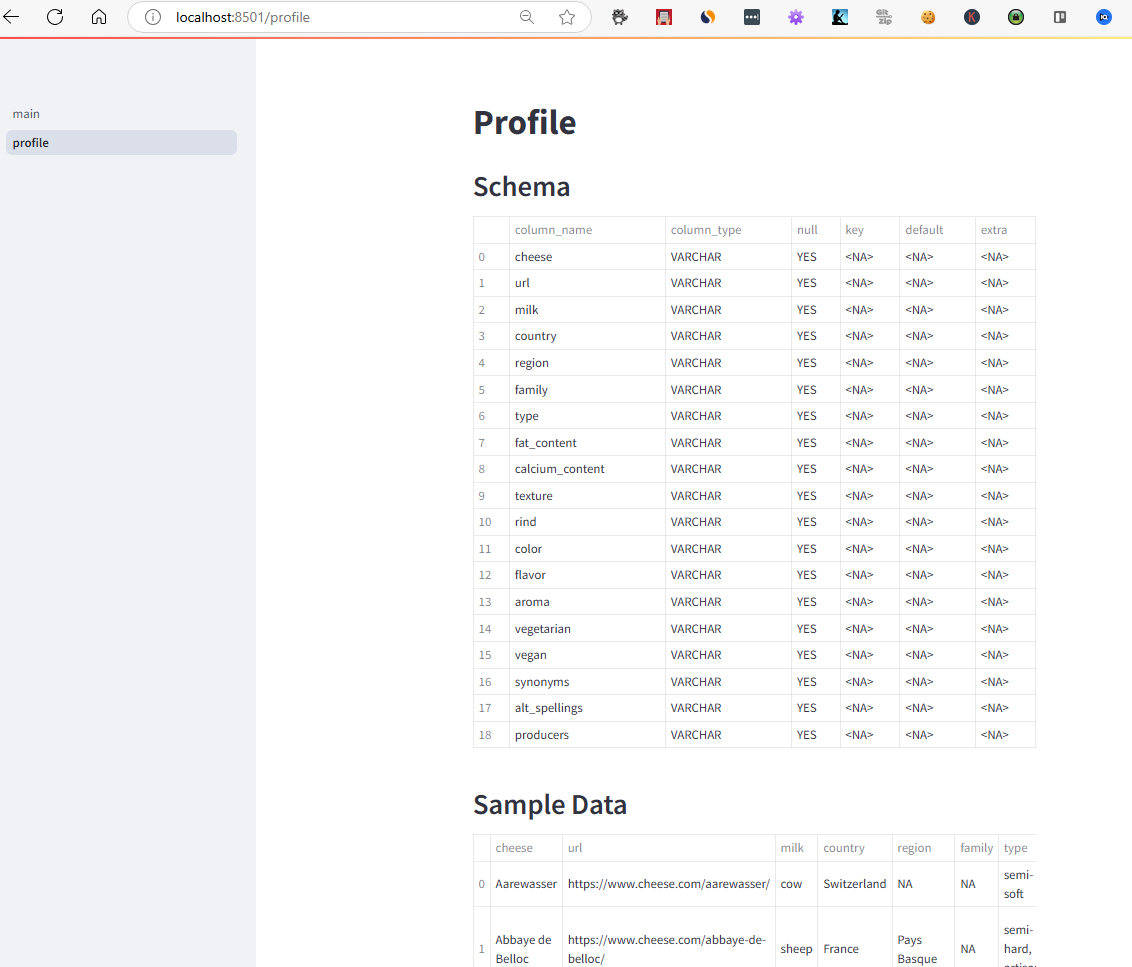
This is purely the entry point page at this point and doesn’t do a lot. For my first page I created a pages directory and added a 1_profile.py file which would display the schema and top 5 rows of the cheeses data. This gives people using this application a quick understanding of the data they are looking at.
import duckdb
import streamlit as st
con = duckdb.connect(database="./data/cheese.duckdb", read_only=True)
st.write("# Profile")
st.write("## Schema")
st.table(duckdb.sql("DESCRIBE SELECT * FROM cheeses;").df())
st.write("## Sample Data")
st.table(duckdb.sql("SELECT * FROM cheeses LIMIT 5;").df())
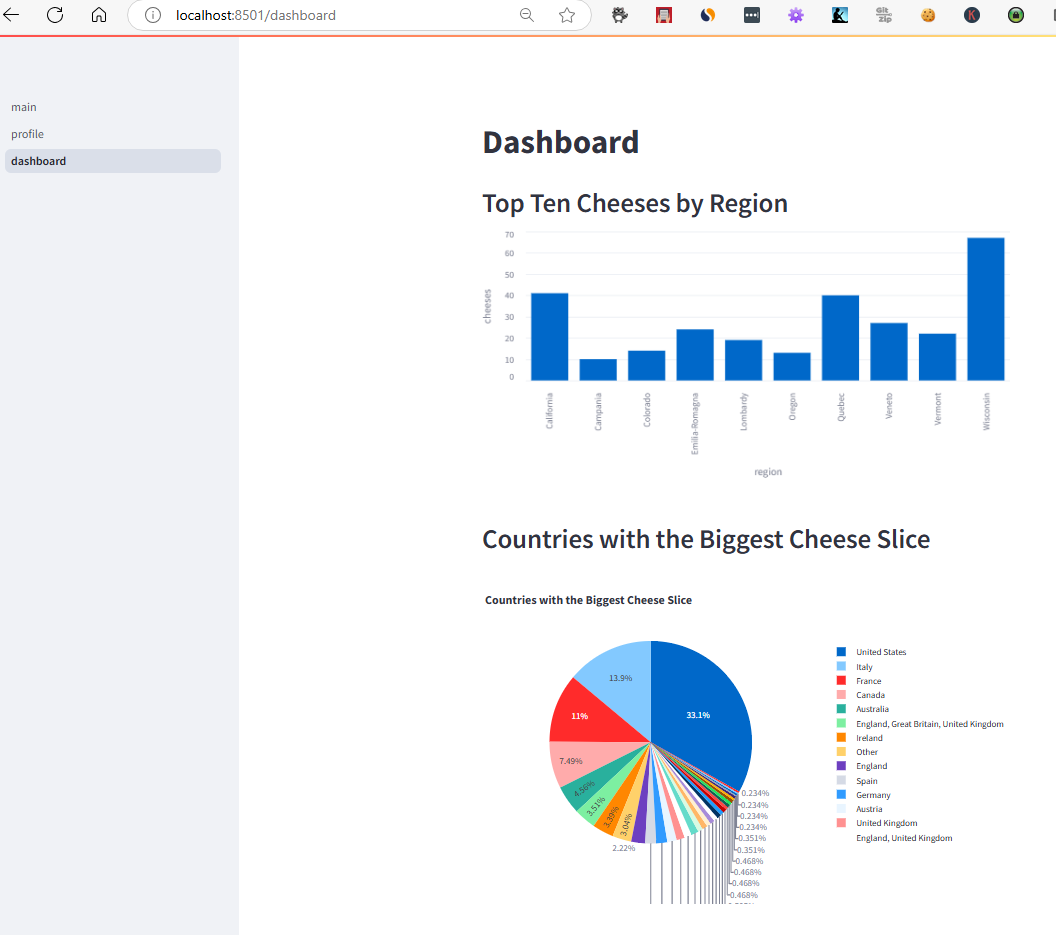
For the second page I added a 2_dashboard.py file which would display the top ten cheeses by region and a pie chart showing the countries with the most cheeses. Notice that the @st.cache_data decorator is used to cache the data so that it is not reloaded every time the page is refreshed. This is a great feature of streamlit that allows you to cache data and only reload it when it changes.
import duckdb
import plotly.express as px
import streamlit as st
st.write("# Dashboard")
st.write("## Top Ten Cheeses by Region")
@st.cache_data
def load_region_data():
df = duckdb.sql(
"""SELECT region, count(*) AS cheeses FROM cheeses
WHERE region <> 'NA'
GROUP BY region
ORDER BY cheeses DESC
LIMIT 10"""
).df()
return df
st.bar_chart(load_region_data(), x="region", y="cheeses")
st.write("## Countries with the Biggest Cheese Slice")
@st.cache_data
def load_country_data():
df = duckdb.sql(
"""WITH CTE AS (SELECT country, count(*) AS cheeses FROM cheeses
WHERE region <> 'NA'
GROUP BY country)
SELECT CASE WHEN cheeses > 1 THEN country ELSE 'Other' END AS country, sum(cheeses) as cheeses FROM CTE GROUP BY all
"""
).df()
return df
# Create a pie chart using Plotly
fig = px.pie(
load_country_data(),
values="cheeses",
names="country",
title="Countries with the Biggest Cheese Slice",
)
# Display the pie chart in the Streamlit app
st.plotly_chart(fig)
Duckdb allowed me to use simple SQL to query the cheeses data along with plotly and barely scratching the surface of the streamlit api offerings, I was able to create a decent looking dashboard with a few lines of code. According to this the good old USA are the biggest cheese monsters of the world!
Containerising the App
My next step was to use trusty containerisation of the python app which would give me the freedom to deploy the application on most clouds. Proving this opens up to a consistent, source controlled and distributed deployment model for reporting just like you would with any other application.
I quickly setup the following dockerfile:
FROM python:3.9-slim
WORKDIR /app
# trunk-ignore(trivy/DS029)
RUN apt-get update && apt-get install -y \
build-essential \
curl \
software-properties-common \
git \
&& rm -rf /var/lib/apt/lists/*
COPY . .
RUN pip3 install -r requirements.txt
EXPOSE 8501
HEALTHCHECK CMD curl --fail http://localhost:8501/_stcore/health
ENTRYPOINT ["streamlit", "run", "main.py", "--server.port=8501", "--server.address=0.0.0.0"]
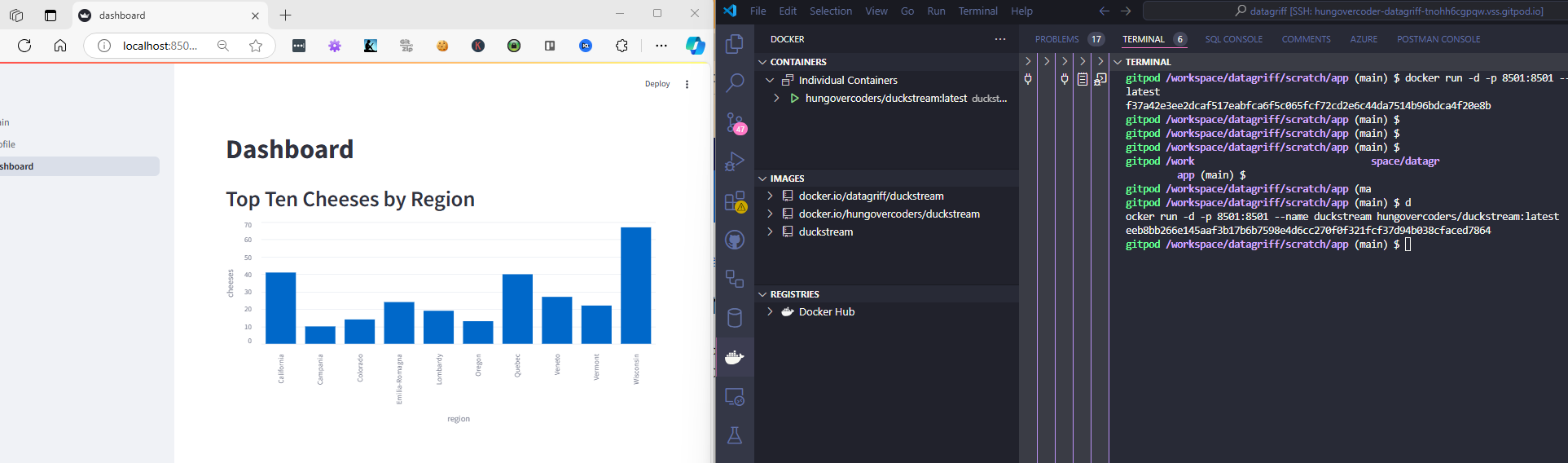
Performed a successful docker build:
docker build . -t hungovercoders/duckstream:latest
And then ran the container successfully:
docker run -d -p 8501:8501 --name duckstream hungovercoders/duckstream:latest
It did seem a little slow to start but eventually you should see the application running on localhost and port 8501. The slowness will have to be investigated further but for now I was happy with the result.
Deploying to Azure Container App
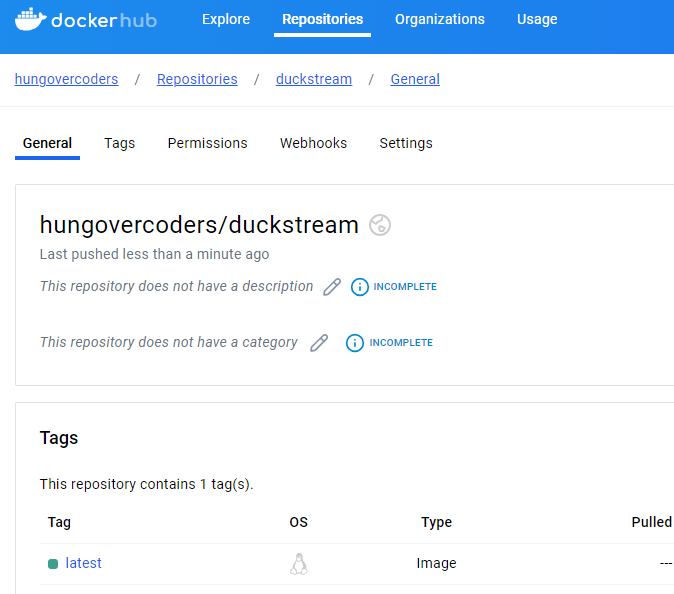
Before I can use the Azure Container App I need to push the container to a container registry. I host the hungovercoder containers in docker hub so I will need to login to docker hub and push the container.
docker login
docker push hungovercoders/duckstream:latest
I could then see the docker image in docker hub.
Next I created an azure container app in the Azure portal GUI…

and selected docker as the registry along with the image of the application.
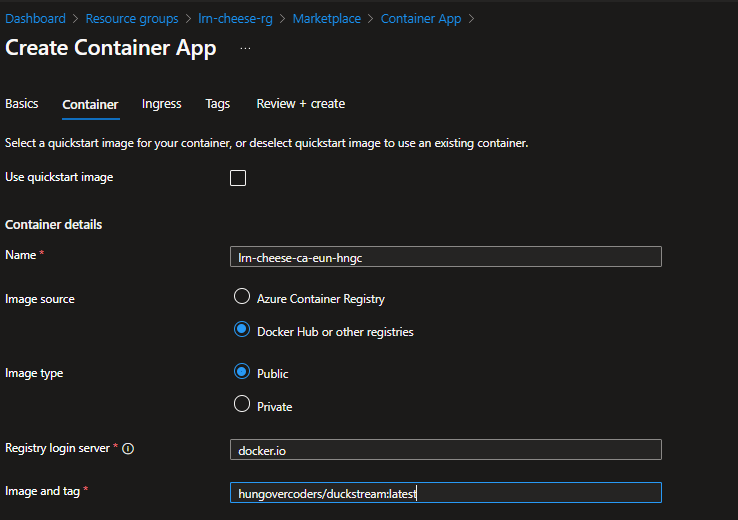
I was then able to view the application running in the azure container app by following the Azure container app URL!
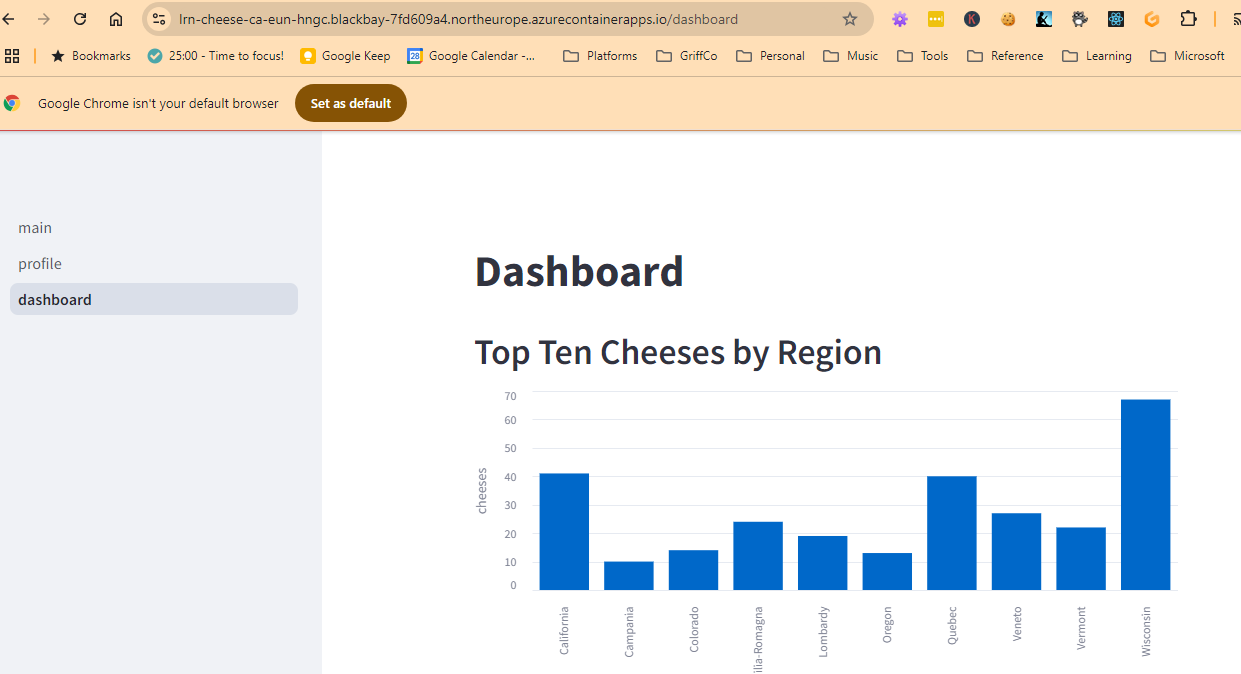
This is super cool as we can also potentially allow the container app to scale to zero so that this application costs nothing when not in use.
Summary
Using duckdb, streamlit and azure container apps we:
- Created a lightweight database solution
- We source controlled our reporting application
- We created a scaled out and cost effective containerised solution for reporting apps that we can repeat to create a distributed reporting mesh
Smoke if you got ‘em!