
Local Install of Spark, Python and Pyspark on Windows
Want to install python, spark and pyspark for some local data pipeline testing? Look no further… Accompanying this blog there is also this video on youtube. Multimedia has hit the hungovercoders!!!
- Pre-Requisites
- Python Install
- Java Install
- Spark Install
- Hadoop WinUtils Install
- Confirm Spark
- Pyspark Install
Pre-Requisites
For testing you’ll need to have an IDE installed, I tend to use visual studio code.
Python Install
Install python by first downloading it from here. Choose the latest version and then the file for your operating system (in this case windows 64-bit).
When you start installing remember to tick “Add Python XXX to PATH” on install to ensure this is set in your environment variables.
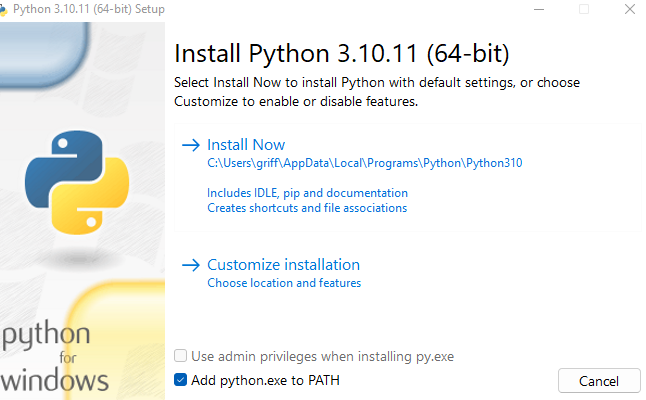
Click install now to complete. Check then in your environment variables to confirm python has been added to your PATH.
Java Install
Go to java downloads and go to download and install.
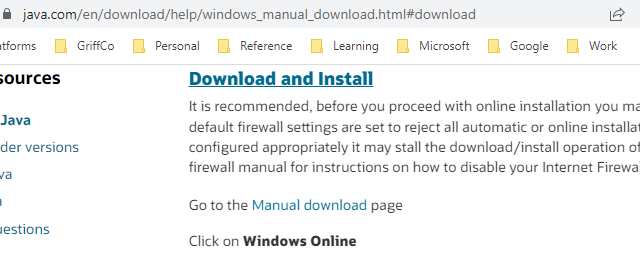
Choose the manual download page. On this page choose windows offline 64-bit.
Install Java by double clicking the executable once downloaded. Once completed confirm that JAVA has been installed by checking the installation location. Then finally add JAVA_HOME and the path to your user environment variables and add the path to java here. For me the path is on my C drive at C:\Program Files\Java\jre1.8.0_271.

Spark Install
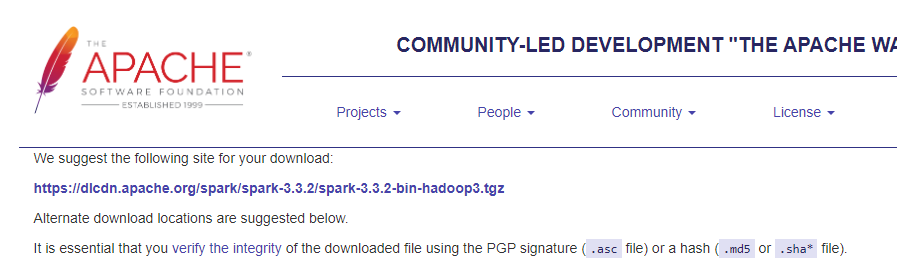
Download spark from here.
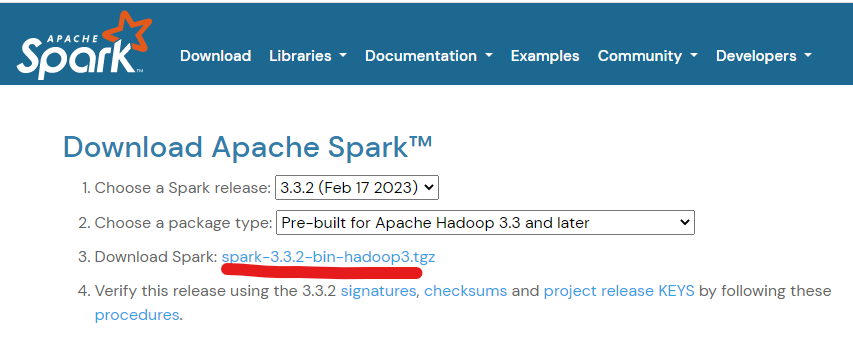
At the top of the download page, choose the suggested site for the tar file download. This will take a little while to download as its quite big.
Note the name of the download as it will tell you which version of hadoop winutils you need to install later. In the instance below it is Hadoop 3.
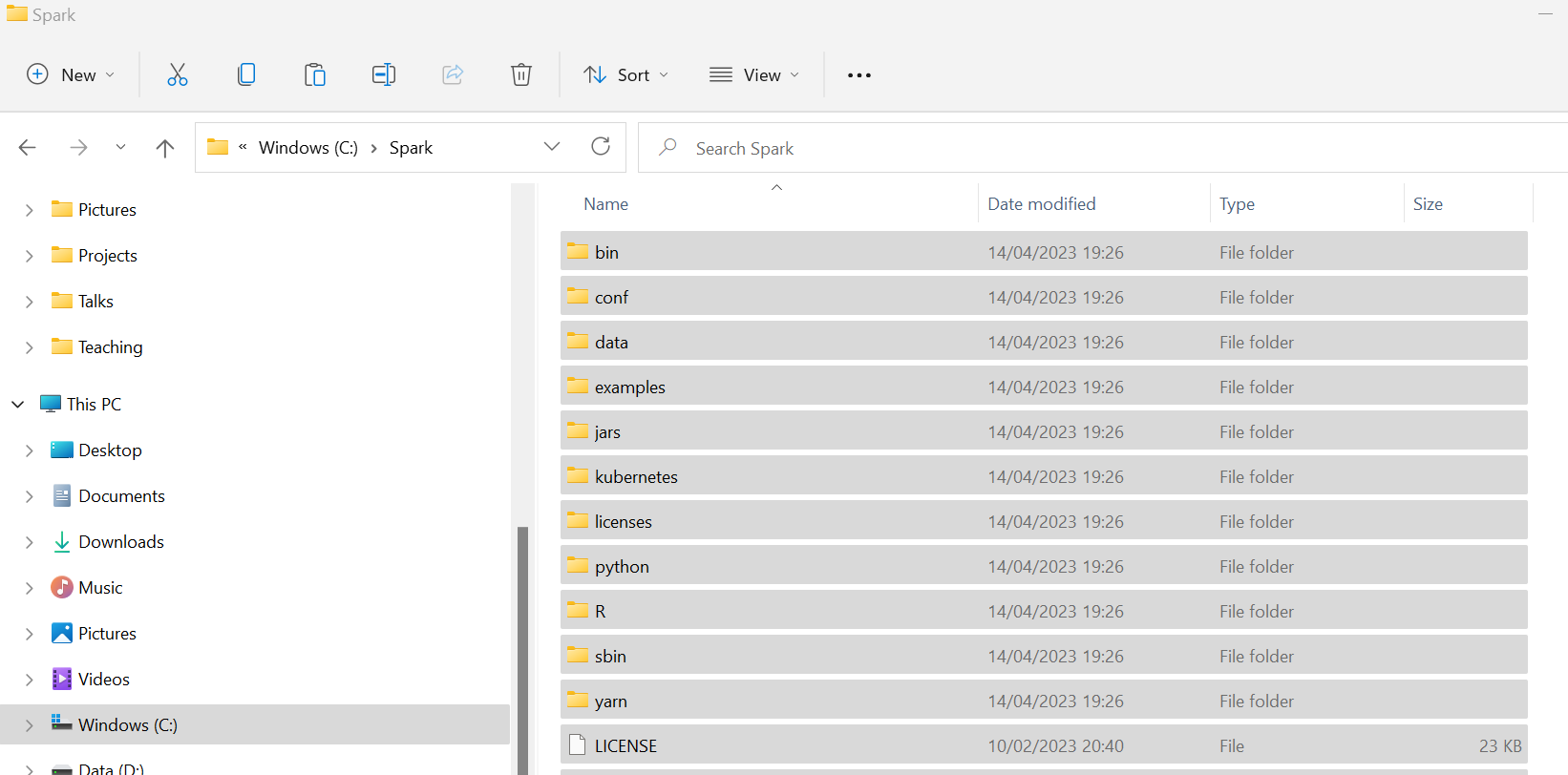
Once downloaded, unzip the tar file twice…
Copy all of the contents of the unzipped file and paste into a location on your C:\drive called C:\Spark.
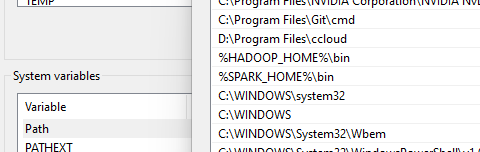
Then add SPARK_HOME to your system environment variables with the value C:\Spark.

Finally add a new Path in your system environment variables with the value %SPARK_HOME%\bin.
Hadoop WinUtils Install
Go to github hadoop winutil.
Download the appropriate winutils.exe. You will know which is the correct one based on the version of the taf file you downloaded for spark.
Add a C:\Hadoop\bin folder your machine and add the winutils.exe to this.
Then add HADOOP_HOME to your system environment variables with the value C:\Hadoop.

Finally add a new Path in your system environment variables with the value %HADOOP_HOME%\bin.
Confirm Spark
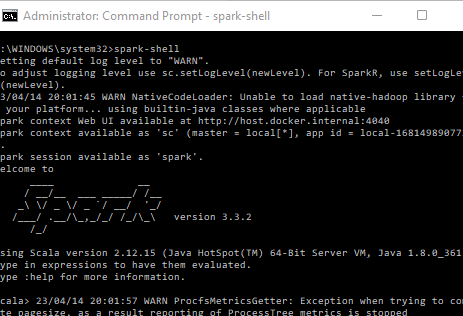
Open a command prompt with admin privileges and run “spark-shell”. You should then see the letter SPARK come up as per below. after a little while.
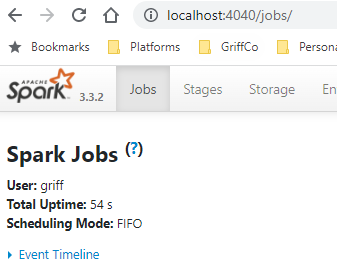
You can also navigate to the local host spark UI here http://localhost:4040/.
Pyspark Install
To install pyspark open up visual studio code. Open a terminal and run the following command to create a virtual environment and pip install pyspark. Ensure you use the correct python version that you installed originally in the command.
py -3.11 -m venv venv
venv\scripts\activate
pip install pyspark
pyspark
In the spark terminal just setup a simple dataframe and display it to confirm functionality.
data = [('Tiny Rebel','Stay Puft'),('Crafty Devil','Mike Rayer')]
columns = ["brewery","beer"]
df = spark.createDataFrame(data=data, schema = columns)
df.show()
The deactivate your environment.
```bash
venv\scripts\deactivate
You have now successfully setup a local environment whereby you can run python, spark and pyspark locally! Time for a drink…